시작하며;
딥러닝 모델을 학습하면서 성능이 일정 수준에서 정체되는 문제를 자주 겪었다. 특히 분류(Classification) 문제에서 모델은 쉽게 구분할 수 있는 이미지에는 꽤 높은 정확도를 보였지만, 조금만 애매하거나 기준이 모호해지는 사례에서는 성능이 급격히 떨어졌다. 이 문제를 해결하고자, 이전 게시글에서 소개했던 방식보다 더 나아가 분류 클래스를 세분화해보기도 했다. 예를 들어 ac, bpd 등 각각에 대해 별도 부정 클래스로 분리해 na_xxx, no_xxx 처럼 구성 후 학습했다. 하지만 결과는 예상만큼 긍정적이지 않았다. 세분화한다고 해서 혼란스러운 사례들이 더 잘 분류되는 건 아니었고, 오히려 전체적인 정확도가 떨어지는 부작용이 생기기도 했다. 처음에는 그 다양성을 반영하려고 세분화를 했지만, 결과적으로는 분류 기준이 애매해지고, 모델이 헷갈리기만 했다.
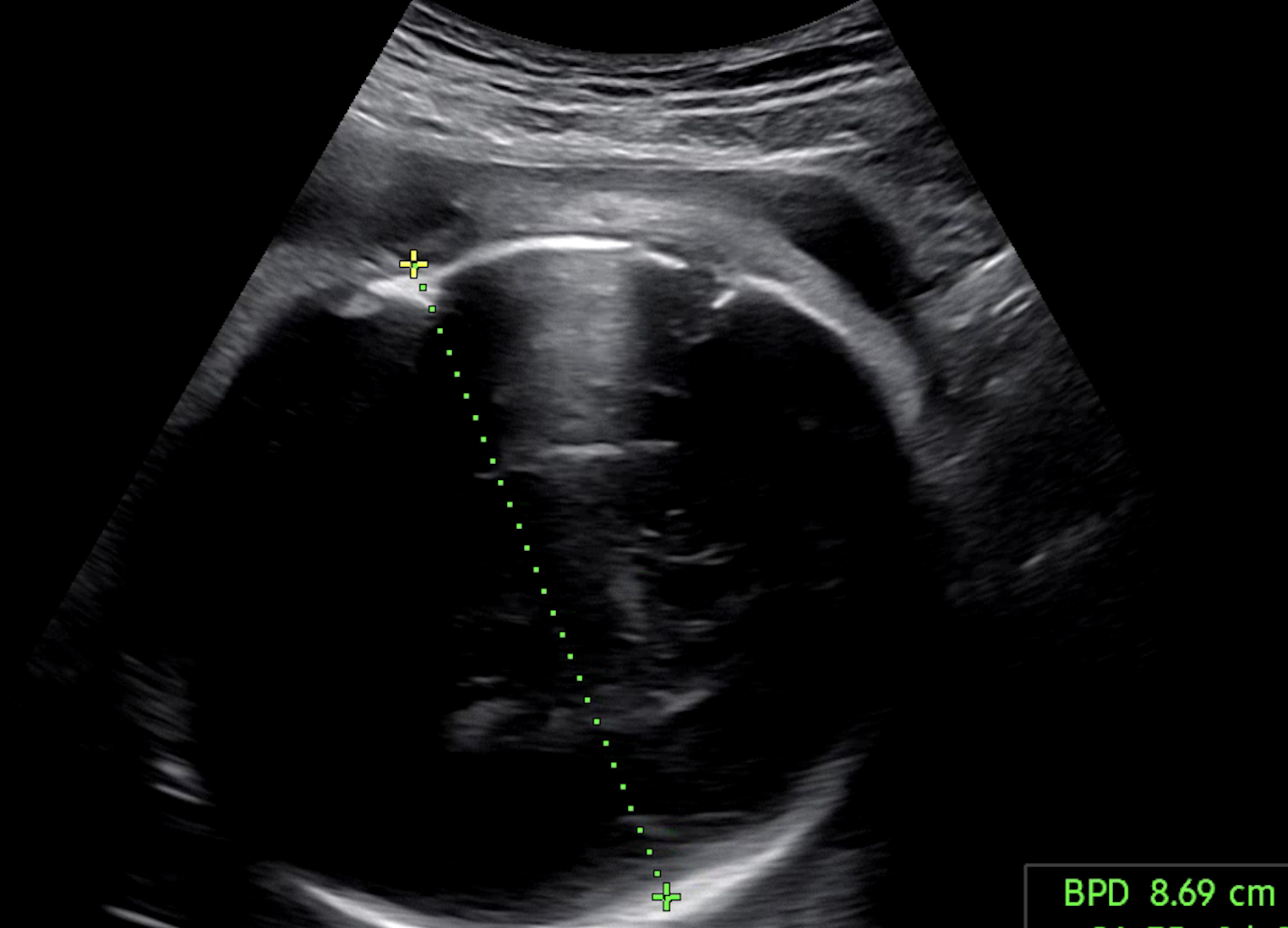
Hard Negative Mining 도입;
다른 메트릭에 비해서 입체 초음파 이미지의 경우, 굉장히 잘 분류되었다. 그리고 그 이유가 궁금했다. chatGPT 나 구글링 통해서 여러 차례... 아니 며칠을 물었다. 입체 초음파의 학습 샘플들이 모델 입장에서 "쉬운 정답들 (Easy Positives/Negatives)" 이지 않았을까.. 싶다. 그리고 로직을 다시 복기해보니 편차가 있는 클래스들 (어려운 부정 샘플 (Hard Negatives)) 은 별도 가중치 없이 학습되고 있다는 것도 깨달았다. 그래서 찾아보다가 Hard Negtive Learning 알게 되었다. 뭐든 해봐야 알 수 있으니 바로 도입해봤다. 학습 순서는 다음과 같다.
- Full Training
- 이 단계에서는 모든 클래스에 대해 균등하게 학습
- 먼저 전체 데이터를 가지고 일반적인 방식으로 학습 진행
- Hard Negative Learning
- 1번 학습 결과를 기반으로, 모델이 혼동하거나 자주 틀리는 부정 클래스들(hard negatives) 선정
- 예를 들어 ac 와 afi 가 자주 헷갈린다면, 경계가 모호한 부정 클래스들에 대한 학습을 별도로 강화
- 이때는 일반적인 샘플이 아니라 실제 예측이 실패했던 사례들을 중심으로 미니배치를 구성하여 focused learning 수행
- Refined Full Training
- 모델이 일부 업데이트된 상태이므로, 다시 전체 데이터를 이용해 한 번 더 full training 진행
- 강조 학습된 정보가 전체 클래스 분포에 자연스럽게 녹아들 수 있도록
이 과정을 반복하면서, 모델은 점점 더 애매한 경계에 있는 이미지들에 대해 분류 성능이 향상되는 모습을 보였다. 마치 인간이 실수를 복기하며 이해를 넓혀가듯, 모델도 실패를 반복해서 학습하며 더 똑똑해졌다.
더 이상 필요없는 HNL 왜?;
25년 7월 12일 기준으로, 기존의 싱글 클래스(single-class) 기반 분류 모델을 멀티 클래스(multi-class) 기반으로 전환하고, 추가로 수행하던 Hard Negative Learning (HNL) 을 더 이상 적용하지 않기로 결정했다. 그 이유는 다음과 같다:
- sigmoid 기반 멀티 라벨 분류에서는 클래스 간 경쟁이 직접적으로 발생하지 않음
→ softmax 구조와 달리 각 클래스를 독립적으로 예측하므로, 경쟁 구조는 내재되어 있지 않음
→ 하지만 하나의 이미지가 여러 클래스를 동시에 포함할 수 있어,
→ 결과적으로 모델이 여러 클래스 간의 경계를 함께 학습하게 됨
→ 따라서 별도의 hard negative learning 없이도 자연스럽게 구분 성능이 향상됨
- HNL 의 목적이 애초에 "단일 클래스 모델의 불완전한 분류 보완"이었음
>> 멀티 클래스에서는 softmax 확률을 통해 애매한 상황에서도 확률 분포로 클래스 간 경계를 자연스럽게 학습함
>> 별도의 오답 노트 학습(HNL)이 불필요
- 멀티 클래스 초기 학습에서도 모든 샘플을 사용함
>> 기존에는 확신이 없는 샘플을 confidence filtering 으로 학습에서 제외
>> confidence filtering 을 제거하고 모든 데이터를 학습함
>> 확신이 없던 클래스도 학습 → 어려운 클래스 성능 향상
결과적으로 멀티 클래스 기반에서 sigmoid 를 사용하고, 전체 데이터를 학습에 활용하면서, 이제는 별도로 Hard Negative Learning(HNL) 을 적용하지 않아도 충분히 구분 성능을 향상시킬 수 있었다. 잘못 예측한 클래스도 자동으로 다시 학습되고, 데이터 전체를 활용해 클래스 간 균형 있게 학습할 수 있으며, 굳이 어려운 샘플만 따로 골라서 반복 학습할 필요가 없었다.
실전;
입체 초음파 분류 자체는 신뢰도가 높은 편이다. 초기 프로토타입에 불과했던 이미지 분류 기능이, 이제는 실서비스에 녹일 수 있을 만큼 안정성과 완성도를 갖췄다. 하지만 나의 최종적인 목표는 다양한 생체 메트릭을 활용/분석해서 의미있는 예측 모델을 만들고 싶다. 그래서 오늘도 삽질 중이다.🔥
return;
멀티 클래스로 전환하게 된 내용에 대해서 남긴 글이다.
2025.07.12 - [딥러닝] - Softmax 만으론 부족했다: 초음파 이미지 분류 문제를 다시 정의하다
'딥러닝' 카테고리의 다른 글
| Softmax 만으론 부족했다: 초음파 이미지 분류 문제를 다시 정의하다 (0) | 2025.07.12 |
|---|---|
| 딥러닝 이미지 분류: 클래스 세분화의 함정 (0) | 2025.07.02 |
| 🧠 Catastrophic Forgetting, 이렇게 시작됐습니다 (0) | 2025.06.03 |
| ResNet18 로 초음파 영상 똑똑하게 분석하기 (2) | 2025.02.06 |



