시작하며;
초음파 이미지 분류 모델을 개발하면서 내가 문제를 어떻게 정의하느냐에 따라 성능이 크게 달라질 수 있다는 사실을 깨달았다. 최초에 나는 이미지를 단일 클래스(single-class) 로 분류하도록 모델을 구성했다. 예를 들어, 이미지가 AC(복무 둘레), BPD(머리 둘레), FL(대퇴 길이) 등 특정 부위를 나타내는 경우, 해당 부위 하나만 예측했다. 하지만 이렇게 구성했을 때, 모델의 예측 정확도는 완벽하지 않았다. 그래서 HNL 을 수행했었다. 일종의 오답 노트 학습처럼, 잘못 분류한 클래스에 집중해서 보완했다. 하지만 다양한 사례를 살펴보면서, 예상하지 못한 경우를 정말 많이 마주쳤다. 결국 이 문제는 단일 클래스가 답이 아니라, 멀티 클래스 구조로 바꿔서 각 클래스 간 확률을 비교하게 해야만 제대로 풀 수 있는 문제였다.
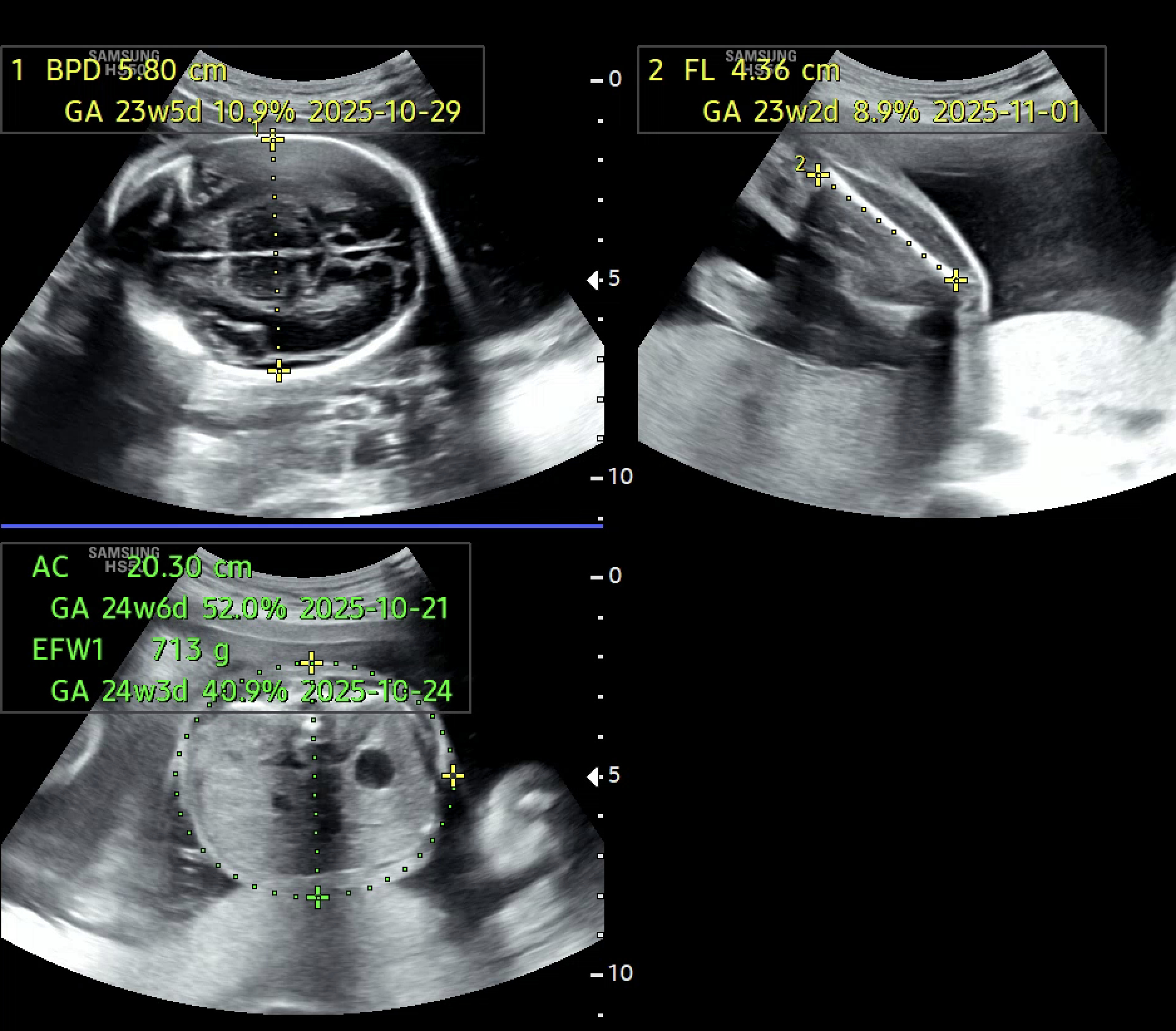
기존 학습 방식의 한계;
기존에는 softmax 기반으로 각 클래스 간 확률을 계산하고, 확률이 충분히 높은 경우에만 학습하도록 설정했다. 추가로 내가 따로 만든 MarkerLoss 를 추가해서 부위 영역 예측 성능을 높이려고 했다. 이후에는 FocalLoss 를 도입해 어려운 샘플에 더 집중하도록 개선했다.
하지만 이런 방식에도 불구하고 몇 가지 한계가 있었다:
- softmax 기반 구조였지만, confidence filtering 으로 인해 데이터의 일부만 학습에 사용되어 데이터 활용도가 낮았음
- 특히 초반 epoch 에 모델이 정확한 확률을 출력하지 못하면 대부분의 샘플이 걸러져서 학습이 제대로 이루어지지 않는 문제 발생
- 클래스 간 경계가 애매한 이미지에서는 확신이 낮은 경우가 많아, 학습에서 누락되는 케이스가 자주 발생함
- Marker 영역 성능 향상을 위해 별도의 loss 를 추가했지만, 근본적으로 모든 데이터를 활용하는 학습이 아니기 때문에 성능 개선에 한계가 있었음
모델이 더 안정적으로 학습하려면 초반부터 모든 데이터를 학습에 사용하고, 확신이 없는 데이터까지 포함하도록 변경했다. 하지만 무엇보다도, 초음파 이미지라는 특성상 한 장의 이미지에 여러 부위가 함께 측정되는 경우도 많다는 사실을 간과하고 있었다. 실제 의료진도 하나의 이미지에서 AC, FL 등 여러 부위를 동시에 측정한다. 하지만 softmax 기반의 멀티 클래스 분류 방식은 무조건 하나의 클래스만 선택해야 하기 때문에, 이런 현실적인 상황을 반영하지 못했다. 결과적으로, 데이터 자체는 멀티 클래스 특성을 가지고 있는데, 모델은 억지로 싱글 클래스로 억지로 해석하고 있었다.
멀티 클래스 방식으로 전환;
출력 방식부터 다시 고민해 보았다. 처음에는 softmax 를 사용해 멀티 클래스 분류를 했는데, softmax 는 모든 클래스 확률의 합이 1이 되도록 강제한다. 이 구조에서는 한 클래스의 확률이 높아지면 다른 클래스의 확률이 자동으로 낮아지기 때문에, 하나의 클래스만 정답으로 선택해야 하는 상황이 된다.
초음파 이미지에서는 하나의 이미지에 여러 부위가 함께 측정되는 경우도 많고, 경계가 모호한 경우도 많아서 이런 단일 선택 방식이 오히려 현실과 맞지 않았다. softmax 처럼 하나의 클래스만 선택하도록 강제하는 구조이기 때문에 오히려 정확도를 떨어뜨리는 원인이 되었다.
그래서 활성화 함수를 sigmoid 로 변경했다. sigmoid 는 각 클래스의 확률을 독립적으로 계산하므로, 여러 클래스가 동시에 높은 확률을 가질 수 있다. 이 구조가 실제 의료진이 여러 부위를 동시에 측정하는 상황과 더 잘 맞았다.
그런데 sigmoid 와 BCE 를 함께 사용할 경우, 계산 과정에서 오버플로우나 언더플로우가 발생할 수 있기 때문에, PyTorch 에서 이를 보완한 BCEWithLogitsLoss 를 사용해 수치 안정성을 확보했다.
아래는 멀티 클래스 기반으로 변경한 뒤의 실제 예측 결과 예시이다. 단일 클래스 방식에서는 하나의 부위만 예측되던 이미지에서, 이제는 여러 부위가 동시에 높은 확률로 예측되는 모습을 확인할 수 있다.
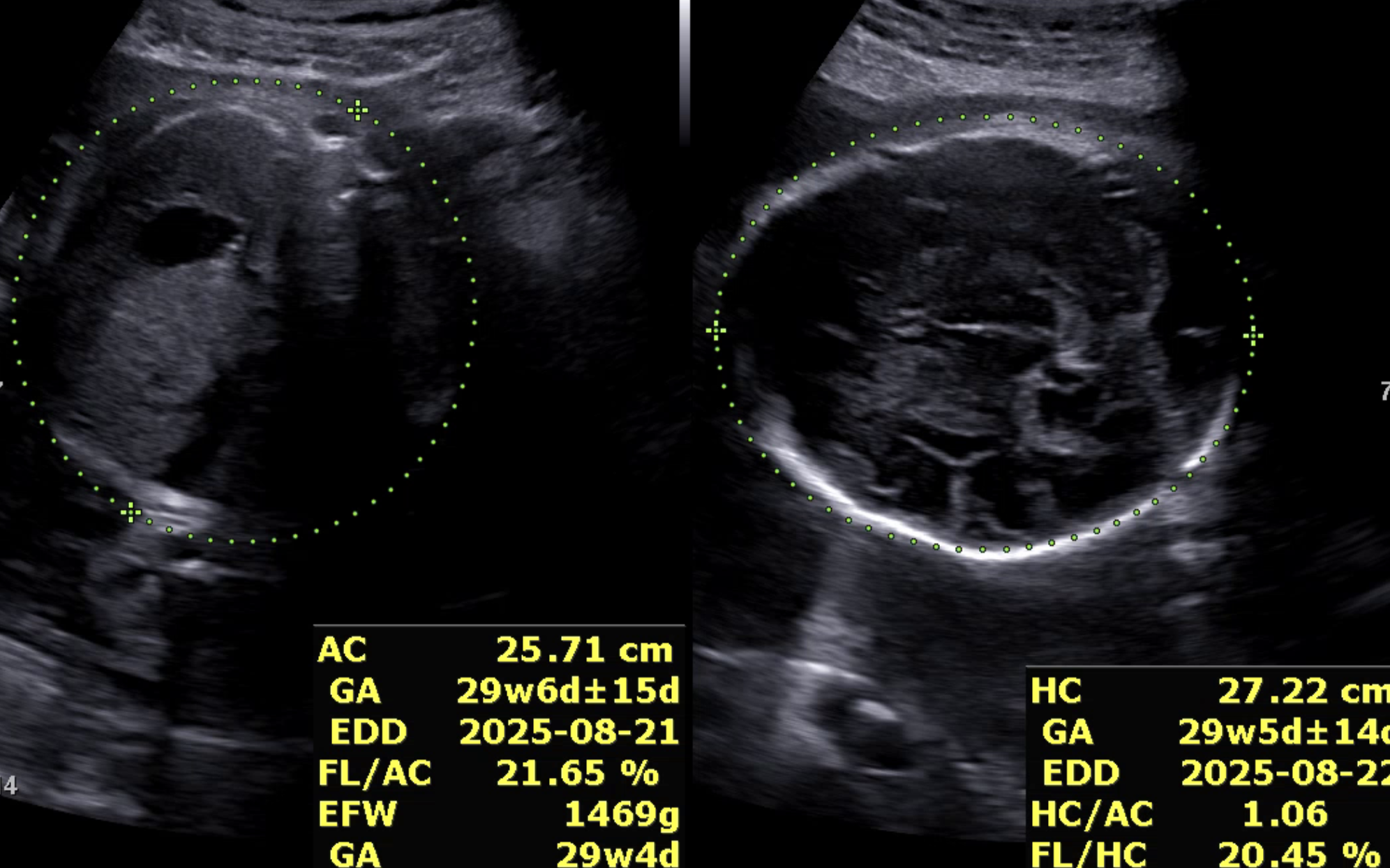
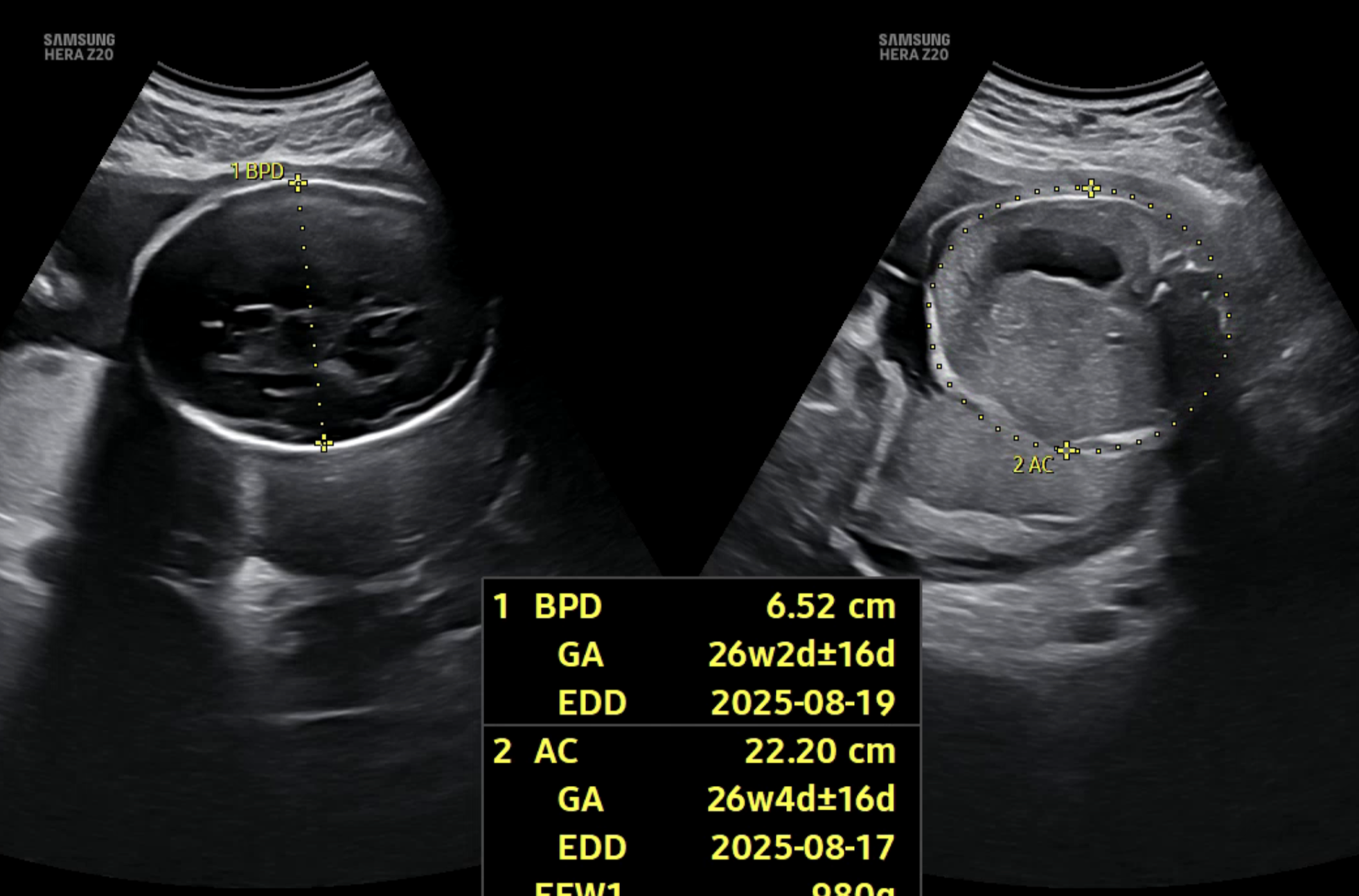


마치며;
출력 방식을 바꾼 뒤, 정확도가 오르고 예측 결과가 더 현실에 가까워지는 것을 보면서 속이 후련했다. 처음에는 loss 함수나 하드 네거티브 샘플링 같은 학습 방식만 계속 손보려 했지만, 결국 본질은 문제를 어떻게 정의하느냐에 있었다는 걸 다시 한 번 깨달았다. 현재는 HNL 을 수행하지 않는다.
이 경험을 통해 성능 개선이 막힐 때는 모델이나 파라미터만 손볼 게 아니라, 애초에 문제를 어떻게 정의했는지부터 다시 고민해 볼 필요가 있다는 걸 배웠다.
return;
'딥러닝' 카테고리의 다른 글
| 딥러닝 이미지 분류: 클래스 세분화의 함정 (0) | 2025.07.02 |
|---|---|
| 🧠 Catastrophic Forgetting, 이렇게 시작됐습니다 (0) | 2025.06.03 |
| Hard Negative Mining: 모델이 틀린 데이터를 다시 학습시키는 방법 (2) | 2025.03.22 |
| ResNet18 로 초음파 영상 똑똑하게 분석하기 (2) | 2025.02.06 |



