시작하며;
초기에는 초음파 영상이 입체인지 아닌지를 구분하는 것이 핵심 과제였다. 하지만 새로운 서비스 준비와 함께, 이미지 분류 기준을 보다 정교하게 세분화할 필요성이 생겼고, 이는 애초에 내가 지향했던 방향이기도 하다. 단순히 입체 여부를 판단하는 것을 넘어, 영상에 어떤 성장 지표가 (예: AC, BPD, FL) 포함되어 있는지를 구체적으로 분류하고 싶었다. 수많은 시행착오 끝에 구조가 또렷이 보이는 이미지는 ac, bpd, fl 등 긍정 클래스로, 구조 식별이 어려운 이미지는 부정 클래스로 나눠 학습시켰다.
여기서 핵심 기준은 영상 내 십자가 모양의 마커와 (marker) 어노테이션의 (annotation) 존재 여부다.
- 마커와 어노테이션 모두 있는 경우 → 긍정 클래스로 분류 (ac, bpd, fl 등)
- 마커는 없지만 어노테이션이 있는 경우 → no_xxx 클래스로 분류
- 마커도 없고 어노테이션도 없는 경우 → na_xxx 클래스로 분류
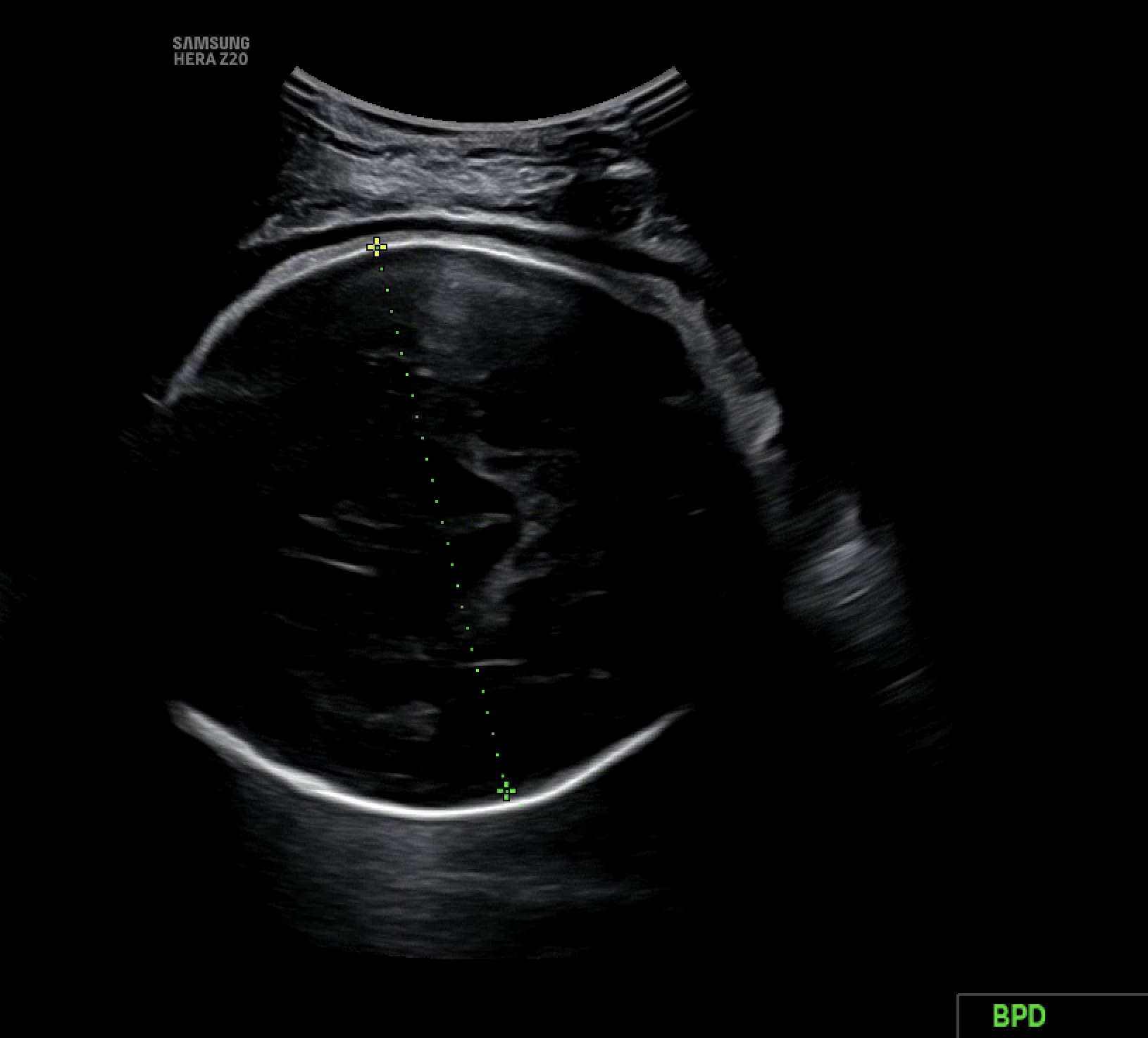
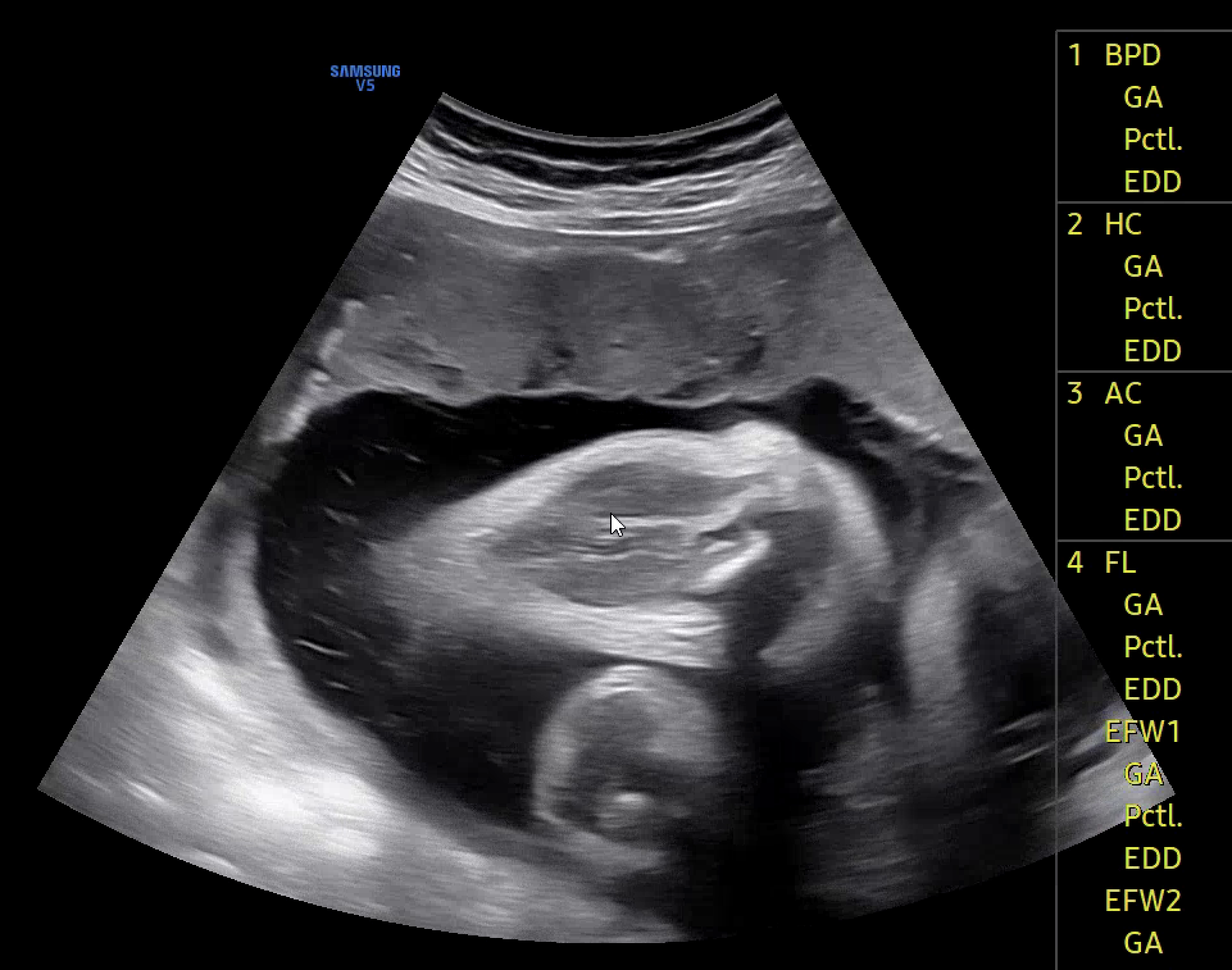
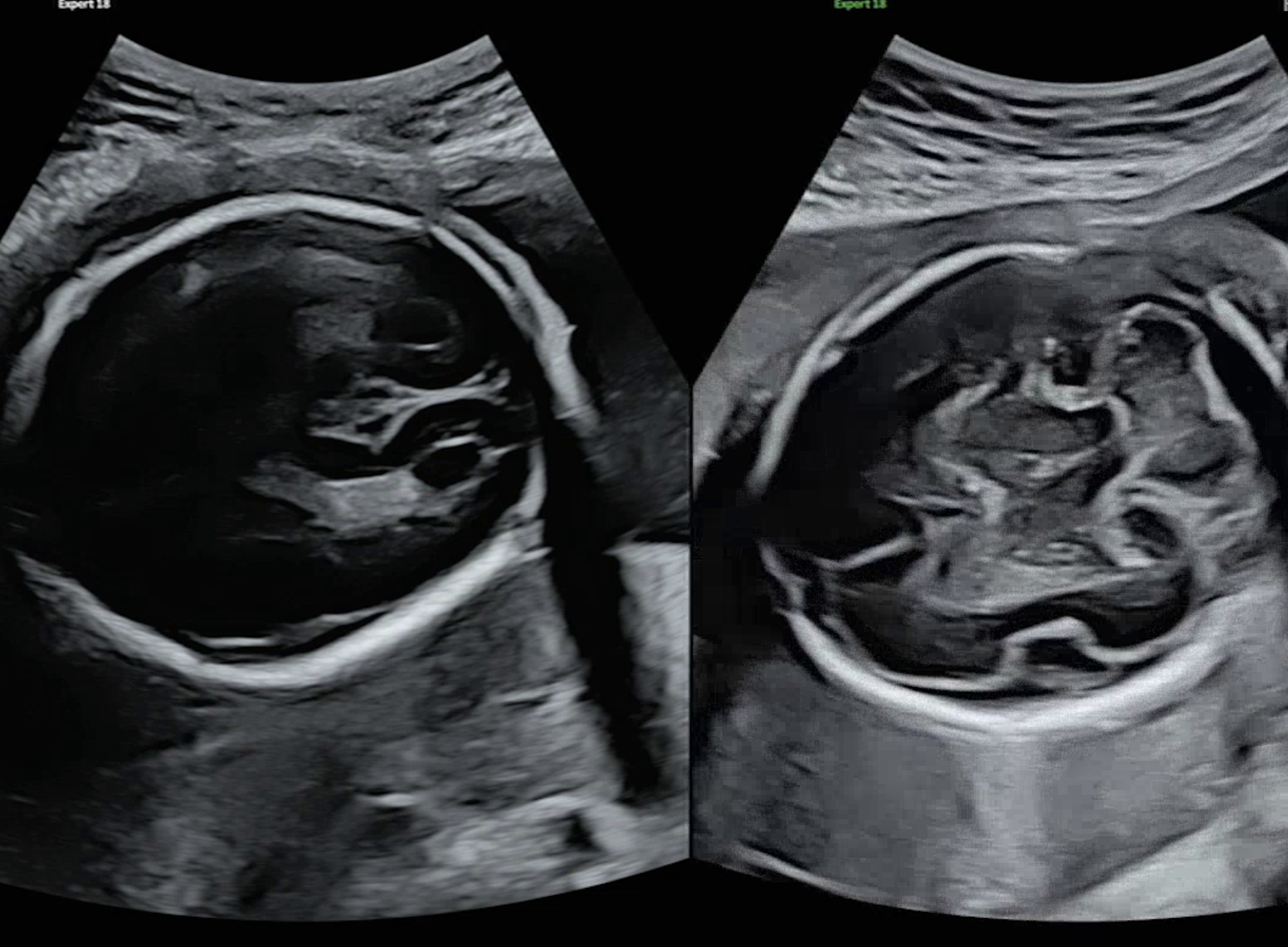
이렇게 이미지 내 구조의 명확성을 기준으로 긍정/부정을 세분화함으로써, 모델이 보다 정밀하게 해당 부위의 식별 가능 여부를 학습하고, 실제 추론 시 혼동 가능성이 높은 사례들을 효과적으로 구분할 수 있도록 했다.
⚠️ 그러나, 세분화의 함정;
각 긍정 클래스에 대응되는 부정 클래스의 학습 이미지를 모으는 일부터 쉽지 않았다. 어노테이션이 없는 상태에선 나조차도 복부 둘레인지 머리 둘레인지 헷갈릴 정도였다. 그럼에도 불구하고, 클래스를 더 세분화할수록 긍정 클래스의 분류 정확도가 높아질 것이라는 가정 아래, 나의 수많은 시간과 비용을 들였다. 사실 정확도가 널뛰듯 오르내리면서도, 간헐적으로 좋아지는 순간들이 있어서 내가 잘하고 있다는 착각도 들었고, 그래서 더 쉽게 멈추지 못했던 것 같다.
아래는 그동안 클래스를 세분화하여 학습한 결과물이다. na_xxx, no_xxx와 같은 부정 클래스들의 정확도가 들쭉날쭉한 모습을 확인할 수 있다. 이 문제를 해결하기 위해, 부정 클래스를 하나로 통합하되 다양한 케이스를 포함시키는 방식으로 바꿔볼까 고민했다. 그리고 실제로 그 방법을 시도해보았다. na_xxx 클래스는 모두 empty 라는 클래스로 통합했고 no_xxx 클래스는 모두 no_marker 라는 클래스로 통합했다.
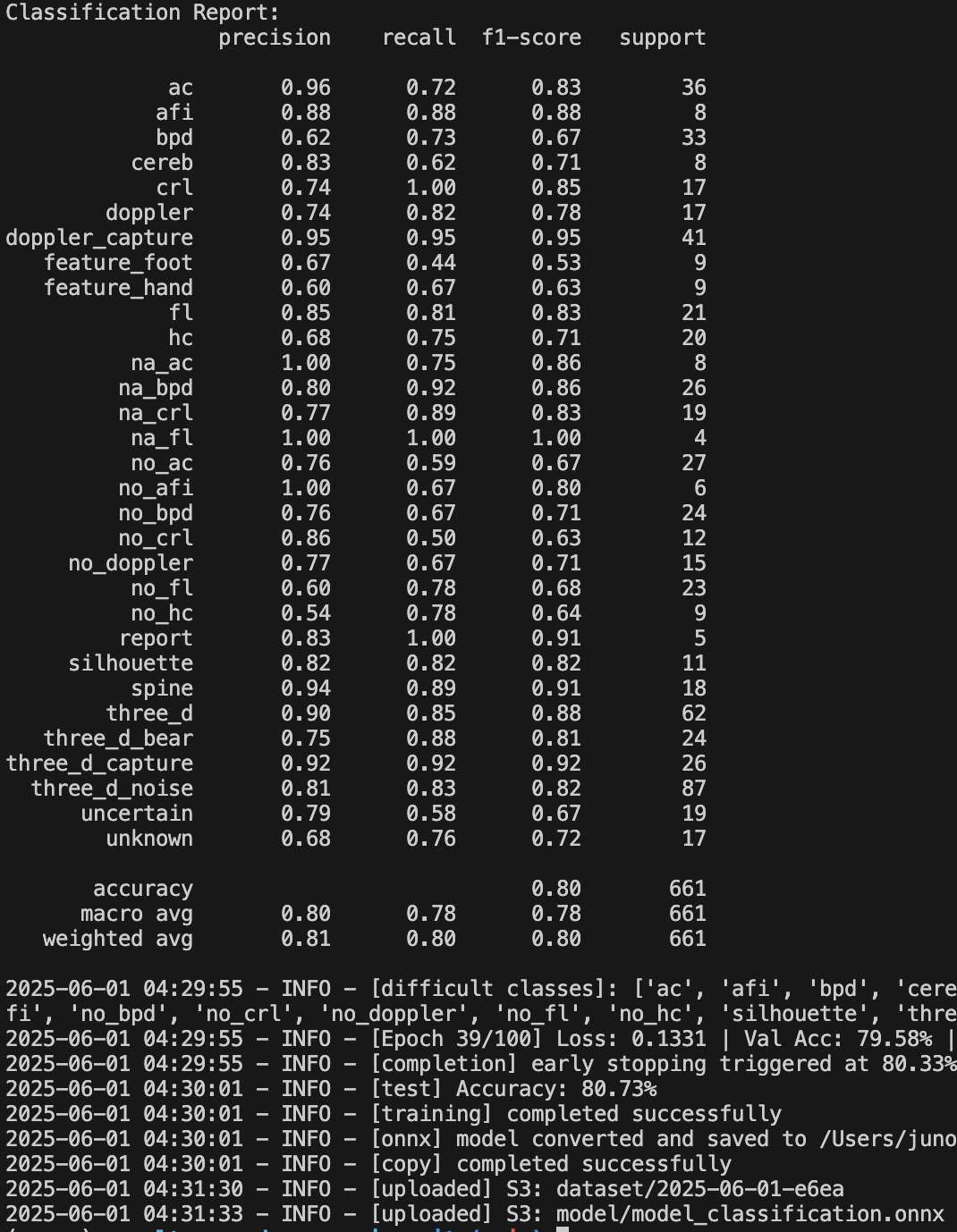
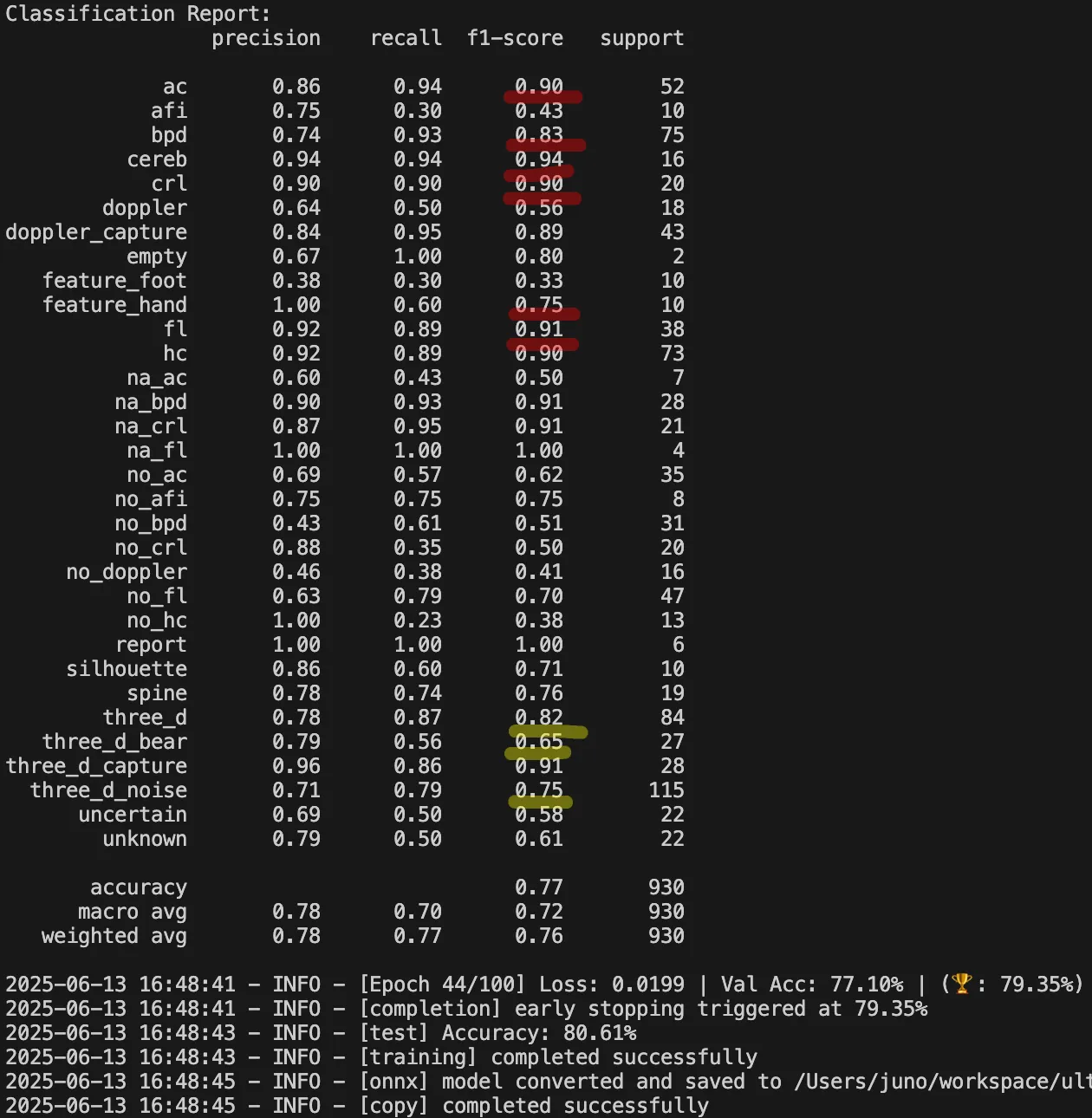
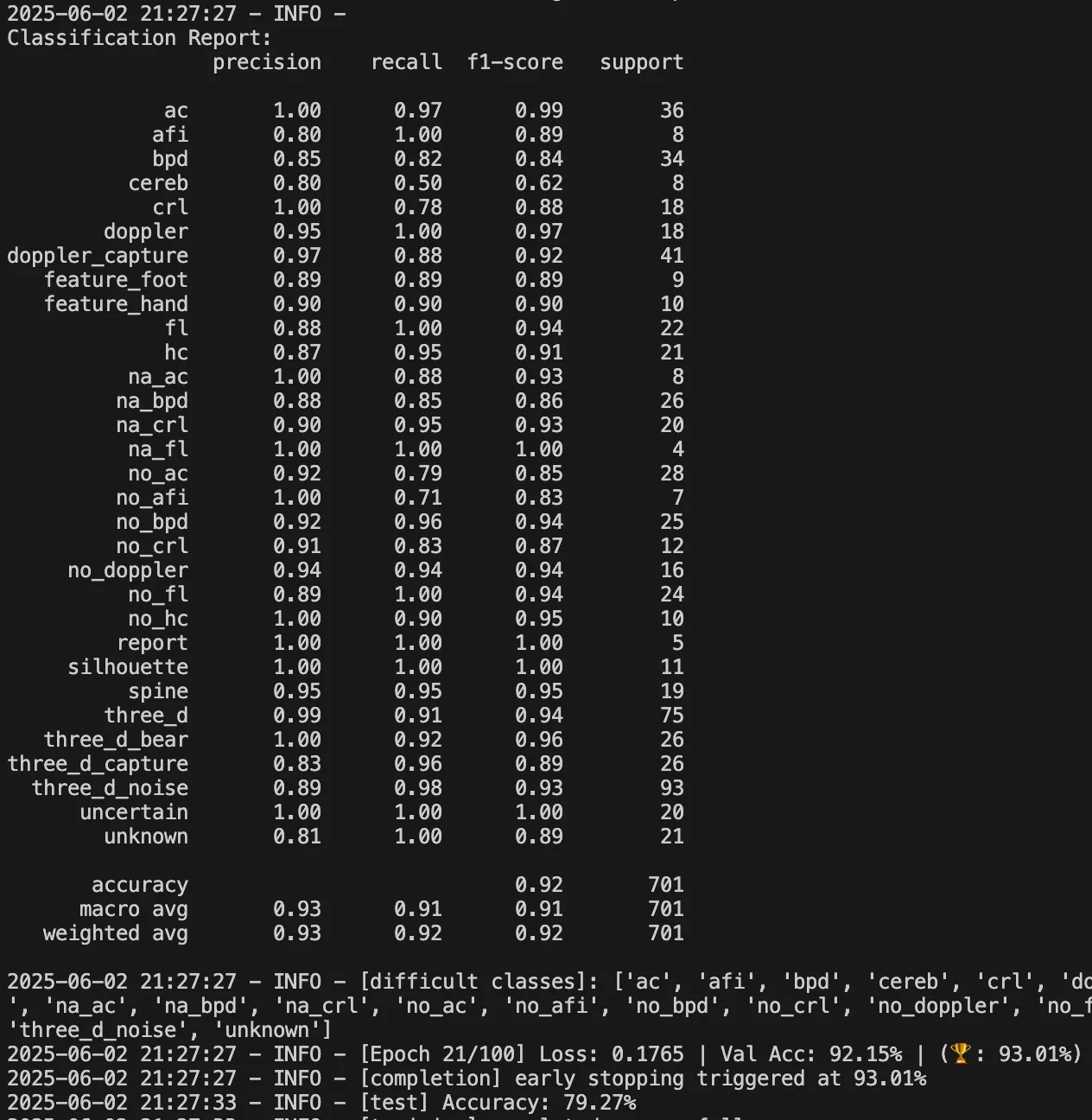
📈 세분화에서 통합으로, 그리고 성능 향상;
새롭게 통합한 부정 클래스로 학습한 결과는 다음과 같다. 확실히 긍정 클래스의 정확도도 함께 상승했다. 분류된 이미지들도 실제로 훨씬 더 안정적으로 동작했다.

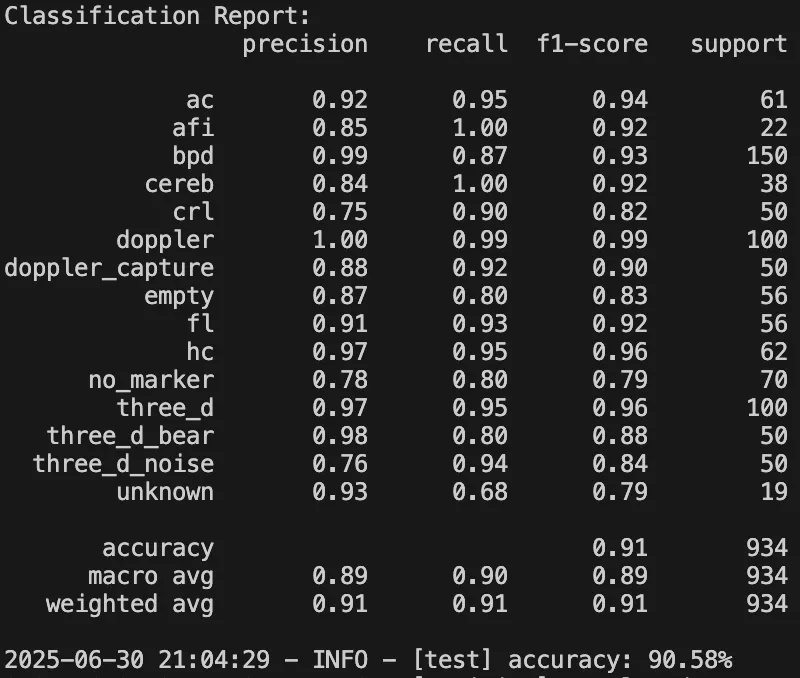
분류 클래스를 세분화했을 때, 내가 기대했던 만큼의 성능이 나오지 않았던 것 이유를 다음과 같이 정리했다.
- 데이터 불균형
- 분류 클래스를 세분화하면 할수록, 특정 클래스에 포함되는 이미지 수는 자연스럽게 줄어들 수 밖에 없다. 즉, 특정 클래스에만 데이터가 몰리거나, 반대로 너무 적은 수의 이미지가 할당되는 클래스가 생기게 된다. 이런 데이터의 불균형은 학습 과정에서 문제를 일으켜, 모델이 일부 클래스에는 잘 작동하지만 다른 클래스는 거의 인식하지 못하는 현상을 초래했던 것 같다.
- 모델 혼란 증가
- 1번(데이터 불균형)과 밀접하게 연결돼 있다.특히 세분화된 클래스들 간의 경계가 명확하지 않아, 모델이 어떤 이미지를 어느 클래스에 분류해야 할지 혼란을 겪었던 것으로 보인다. 예를 들어, BPD 와 CEREB (소뇌)은 초음파 영상에서 육안으로 보기에 매우 유사한 경우가 많다. 하지만 학습 데이터를 구성할 당시에는 이러한 경계의 불명확성을 충분히 고려하지 못하고, 내 주관적인 기준에 따라 "감"으로 라벨링을 진행한 부분이 있었다.
- 모델 용량의 낭비
- 클래스를 늘리면 모델 출력 차원도 커지고, Softmax 는 그 중 하나만 선택해야 한다. 그런데 클래스가 많아질수록 경쟁이 심해지고 적은 데이터의 클래스는 Softmax 에서 밀려나는 확률이 높아지지 않았나 생각한다.
- 데이터가 분산됨
- "마커 없음" 이라는 하나의 중요한 신호가 no_ac, no_bpd, no_fl 등으로 분산되면서, 각 클래스마다 학습해야 하는 가장 중요한 패턴에 ("마커 없음") 집중하지 못했던 것 같다. 모델 입장에선 데이터가 쪼개져서 학습하기 어려워지지 않았나 싶다.
- 결과적으로 성능 향상을 기대하고 세분화를 진행했지만, 이런 이유로 전체적인 분류 정확도가 하락했다고 생각한다.
📝 회고: 더 많은 클래스가 항상 더 좋은 건 아니다;
"세분화된 클래스 = 더 높은 정확도" 라고 믿었다. 과거에 구조물이 조금만 달라도 다른 클래스로 나누는 시도를 여러 번 했었다. 하지만 삽질을 통해 세분화 자체가 목적이 되면 오히려 모델은 혼란스러워진다는 걸 깨달았다. 깨달은 점은 크게 다음과 같다.
- 사람도 헷갈리는 분류 기준이면, 모델은 더 헷갈린다
- 부족한 클래스는 통합해서 "공통된 의미"로 학습시키는 게 더 강력하다
- 나 자신한테 "설명"하기 위한 기준을 세우지 말고 모델 입장에서 데이터를 "분류"할 수 있는 기준을 세우자
return;
2024.12.31 - [이미지 처리] - 끝날 때까지 끝난 게 아니다, 불-편
2025.07.12 - [딥러닝] - Softmax 만으론 부족했다: 초음파 이미지 분류 문제를 다시 정의하다
'딥러닝' 카테고리의 다른 글
| Softmax 만으론 부족했다: 초음파 이미지 분류 문제를 다시 정의하다 (0) | 2025.07.12 |
|---|---|
| 🧠 Catastrophic Forgetting, 이렇게 시작됐습니다 (0) | 2025.06.03 |
| Hard Negative Mining: 모델이 틀린 데이터를 다시 학습시키는 방법 (2) | 2025.03.22 |
| ResNet18 로 초음파 영상 똑똑하게 분석하기 (2) | 2025.02.06 |



