시작하며;
매일 퇴근 전, 그날 학습에 사용할 데이터를 정리하고 모델을 학습시키는 과정을 반복해 왔다. 그러나 어느 순간부터 새로 추가한 이미지에 대해 모델이 제대로 예측하지 못하는 문제가 발생했다.
처음에는 학습률(learning rate)의 문제라고 판단하여 여러 차례 값을 조정해 보았고, 기존에는 잘 분류되던 이미지까지 틀리는 현상을 확인한 후에는, 수백 장의 기존 데이터를 직접 다시 검토하기도 했다. (다 합치면 수 천장.. 을 눈으로 다시 확인 - 오히려 좋아) 그러나 이러한 시도들만으로는 문제를 해결할 수 없었다.
이후, 새롭게 추가된 이미지와 기존 데이터 간의 학습 비중 불균형이 원인일 수 있다는 판단 하에, 학습 데이터 구성 방식과 학습 전략 전반을 다시 점검하게 되었다.
본 글에서는 문제의 원인 분석 과정과 함께, 이를 해결하기 위해 적용한 두 가지 전략인 "최근 이미지에 대한 가중치 부여"와 "Replay Buffer 도입" 에 대해 공유하고자 한다.
문제 상황;
ResNet18 기반의 이미지 분류 모델을 새롭게 수집한 초음파 이미지로 fine-tuning 하는 과정에서 다음과 같은 현상이 발생했다. 처음엔 단순히 데이터만 늘려서 fine-tuning 하면 잘 될 줄 알았다. 하지만 모델이 새 이미지를 제대로 학습하지 못하고, 오히려 전체 성능이 망가졌다.
예를 들어, FL 이라는 새로운 클래스를 추가해 학습을 시켰음에도, 모델은 해당 이미지를 계속 엉뚱한 클래스로 분류했다. confidence 는 낮고, 예측 결과는 불안정했다. 단순히 데이터만 넣는 것으로는 모델이 새호운 학습 이미지를 잘 받아들이지 못한다는 걸 체감했고 답답했다.
딥러닝 모델을 기존 학습 데이터와 새로운 데이터로 연속 학습하려고 하면 종종 다음과 같은 현상을 겪는다고 한다. 모델이 이전 데이터에 대한 성능이 급격히 저하되는 이슈인데, 이를 "Catastrophic Forgetting" (파국적 망각) 이라고 한다.
해결 전략;
"최근에 들어온 데이터가 적어서 그런가?"
"최근 이미지에 가중치를 더 주면 자주 등장할 테니까, 학습이 좀 더 잘 되지 않을까?"
"그럼 예전 데이터들의 특징도 주기적으로 학습시켜줘야 하는 건 아닌가?"
"최근 이미지에 가중치 주기"
그래서 WeightedRandomSampler 를 활용해, 최근 이미지에는 3.0, 기존 이미지에는 1.0 의 가중치를 적용해봤다. 결과는 바로 확인할 수 있었다. 새로 추가한 이미지에 대한 confidence 가 빠르게 상승했고, 기존 이미지에 대한 성능도 아직까지는 크게 무너지지 않았다. 이어서 기존 데이터에서 쌓아온 기반이 무너지면 안 되니깐 또 다른 전략도 함께 고민했다.
"과거 데이터를 잊지 않게, Replay Buffer 전략"
과거 이미지를 일부 랜덤하게 샘플링해서 계속 같이 학습시키는 전략을 추가했다. 이 방식의 핵심은 최근 데이터에만 집중하지 않고, 과거 데이터를 적절히 섞어주는 것이다. 이렇게 하면 모델이 새로운 클래스를 학습하면서도 기존의 분류 성능을 유지하는 데 도움이 된다.
def _sample_replay_buffer(self):
count = min(self.replay_count, len(self.loader.dataset))
replay_indices = torch.randperm(len(self.loader.dataset))[:count]
samples, labels = [], []
for idx in replay_indices:
sample, label = self.loader.dataset[idx]
samples.append(sample)
labels.append(label)
return torch.stack(samples), torch.tensor(labels)효과는?
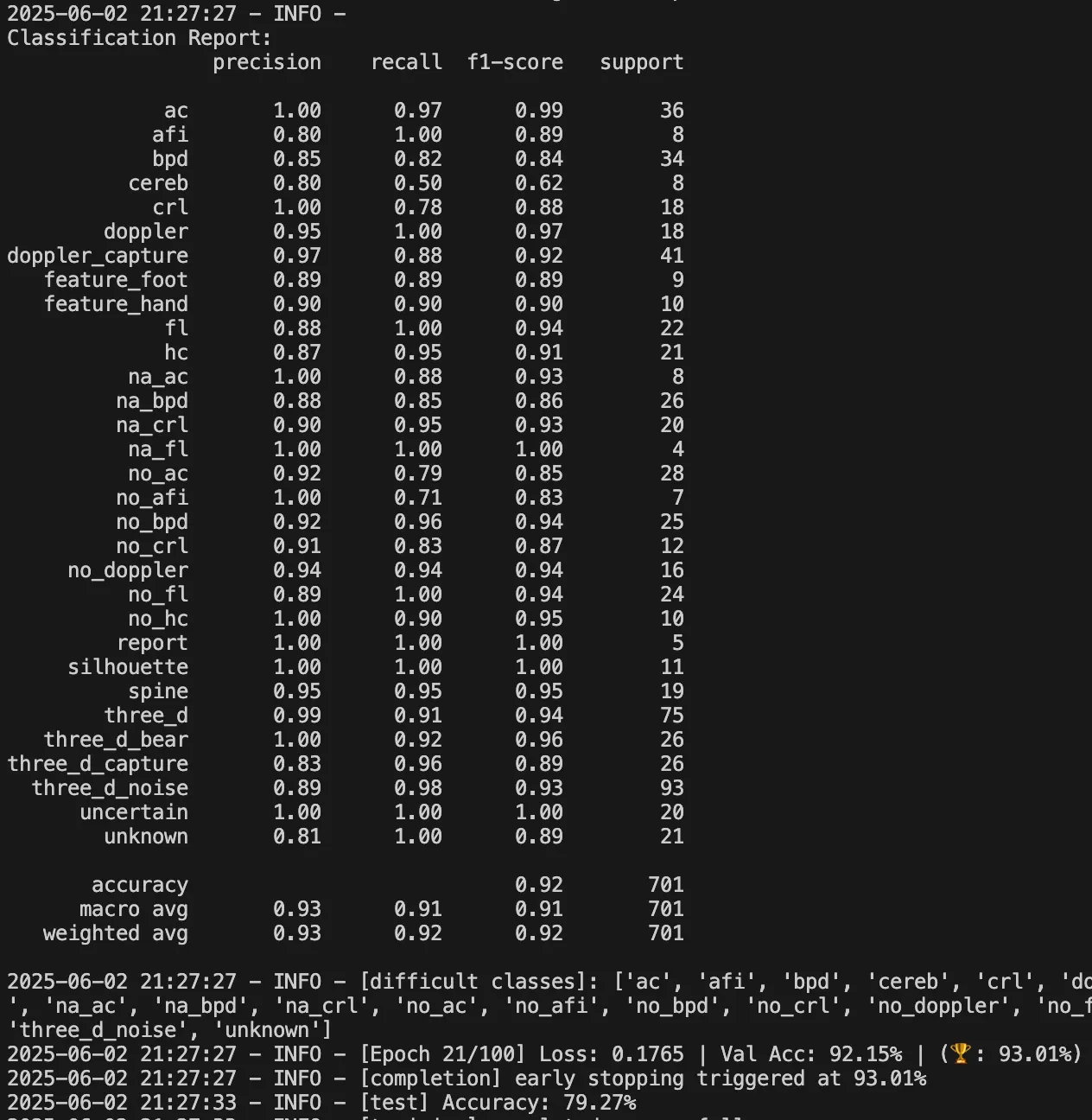
(아직 진행 중) 최고 Validation Accuracy 는 93% 에 도달했다. 거기에 weighted F1-score 는 0.92 까지 상승했다. 심지어 기존에 "어렵다"고 찍혔던 클래스들도 대부분 0.9 이상의 F1을 기록했다.
return;
'딥러닝' 카테고리의 다른 글
| Softmax 만으론 부족했다: 초음파 이미지 분류 문제를 다시 정의하다 (0) | 2025.07.12 |
|---|---|
| 딥러닝 이미지 분류: 클래스 세분화의 함정 (0) | 2025.07.02 |
| Hard Negative Mining: 모델이 틀린 데이터를 다시 학습시키는 방법 (2) | 2025.03.22 |
| ResNet18 로 초음파 영상 똑똑하게 분석하기 (2) | 2025.02.06 |



